

My deep dive into Zero-Knowledge Proofs
I’ve been full-time in the blockchain space for 2-3 years now and studied the most important protocols. I learned the basic principles of Zero-Knowledge Proofs (ZKP) already a long time ago. However, just a couple of months ago, I had nearly zero knowledge of how things work under the hood and what the ecosystem looks like. Certain smart people in the space got me convinced that ZKPs would be worth studying more. I sensed my inner mimetic desire growing and I decided to deep dive and learn.
It’s been fascinating to learn some fundamental cryptography and prime number math after so many years. I decided to compile this blog post to consolidate my learnings.
If you are new to ZKPs but familiar with crypto basics, I hope this blog post serves as a good primer for you to familiarize yourself with the ZKP basics and the current state of ZK-Rollups to scale Ethereum.
I’ll stay on a conceptual level in this article and touch only the surface of the complicated ‘moon math’. Expect about 20 min reading, though.
If you’d prefer a summary, here you go: [Tweet thread summary of the article]
Why are Zero-Knowledge Proofs important?
Ok, your time is limited. And this article is long.
Why should you care — why Zero-Knowledge Proofs are important to understand?
Here’s how Srikar Varadaraj formulated it:

Also, over the years, Vitalik Buterin himself has written 14 long-form articles about Zero-Knowledge Proofs, probably more than any other topic.
Vitalik’s writings have been a clear predictive force of what will be relevant in the space. Just have a look at the original Ethereum whitepaper from 2014 and you’ll find out that many of the ideas have been implemented years later. Another crystal ball writing is on Market Makers from 2017, where Hayden Adams picked up the idea and developed Uniswap (today > 5 Bn market cap protocol).
Zero-Knowledge tech and zk-Rollups most likely won’t be an exception. If Vitalik raves about this, there must be something.
Convinced? Ok — let’s go.
Table of Content
Introduction
Centralized fall down & Progress in protocols
Scalability Nightmare has persisted
Speed is a requirement for many apps
Vitalik’s trilemma & L2 scaling
So, what is Zero-Knowledge Proof exactly?
Required properties for Zero-Knowledge Proofs
Who invented Zero-Knowledge Proofs?
Hypothetical examples of ZKP
Mortgage Risk Assessment
Proving you are over 18 years old
Practical blockchain examples already in use
Privacy coins
Mixers
Ethereum L2 Zk-Rollups
ZK-Rollups for L2 Ethereum scaling solutions
Different ZKP versions
ZK-SNARK
ZK-STARK
ZK-SNARKS proof generation under the hood
Computation
Arithmetic circuit
R1CS
QAP
zk-SNARK
Finally, it is complex
Ethereum scaling: Zero-knowledge rollups
Optimistic rollup vs. zk-Rollups
From A Simple ZK-Rollup to ZK-EVM
Different zkEVMs -- Compatibility differences
Vitalik's zkEVM Categorization
Type 1 zkEVMs: Fully Ethereum-equivalent
Type 2 zkEVMs: Fully EVM-equivalent (not Ethereum-equivalent)
Type 3 zkEVMs: Almost EVM-equivalent
Type 4 zkEVMs: High-level-language equivalent
Comparing zkEVM projects
zkSync
Scroll
Polygon zkEVM
Starknet
Privacy & Scaling Explorations team
Latest news
ZK-Rollup wars & State of L2 Scaling
Final thoughts
Thank you
References
References
Vitalik's writings about ZKPs over the years
Centralized fall down & Progress in PROTOCOLS
First, let’s see where we are today with crypto markets and what is still one of the main pain points.
Last year 2022 was quite a ride in the blockchain space, to say the least. While several centrally-managed entities (FTX, Celsius, BlockFi, Voyager, Genesis, etc) have ended up in bankruptcy, the ‘true’ decentralized smart contract protocols (think of Aave, Maker, Uniswap etc) have crunched the transactions and liquidations without any hiccup.
Code and major decentralized protocols have performed much better than greedy and biased humans. Amidst the collapses of centralized entities, there’s been serious progress in many areas of the decentralized protocols. Also, the Ethereum Merge finally happened, and there are plenty of new L2 protocols, and new dapps e.g. in social space… a lot of progress and experiments.
In a world where entire countries or presidents are cancelled, there is increasing demand for uncensorable, programmable global consensus systems,value transfer and record-keeping.
However, scalability remains one of the fundamental challenges in the blockchain space to truly enable these applications. Scalability is improved by several teams and projects. Let’s see where we are today.
Scalability nightmare has persisted
Ethereum’s average transaction fees. (Source)
Yeah, I remember paying over 50 USD for transactions on Ethereum L1 many times during 2021 and 2022. Prices were over 20 USD for most of the year. It was the normal market rate. Block demand was high.
Naturally, these rates are too high for any serious mass-market adoption or applications.
SPEED is a requirement for MANY Dapps
The speed and cost of using blockchains need to go down. Regular users expect cheap and instant transactions. It is not only ‘nice to have’ — it’s a necessity for certain types of apps (think of e.g. social media apps with each post/comment counting as a transaction). A quick and smooth user experience is a must-have for larger adoption.
Vitalik’s trilemma & L2 scaling
After many years, Vitalik’s trilemma of Scalability, Security and Decentralisation seems to be an eternal area to improve in blockchain development. The rule of thumb says that you can only have two out of three characteristics in one public blockchain.

Scalability Trilemma, https://vitalik.ca/general/2021/04/07/sharding.html
For example, Ethereum has been considered to be Secure and Decentralized (thousands of nodes), but the scalability has been a limiting factor (only 15 transactions per second). When the demand is high, the Ethereum mainnet can be extremely expensive to use.
There have been many new L1s launched during the last few years. They have a different balance of the aforementioned three qualities. E.g. Solana has always focused on Scalability by compromising on Decentralization.
Ethereum’s L2 scaling solutions (e.g. Optimism and Arbitrum) have helped Ethereum quite a bit. So did The Merge (change of consensus mechanism from Proof-of-Work to Proof-of-Stake). But transaction costs have still been above 1 dollar. Imagine paying 1 dollar just for commenting on your friend’s post on decentralized social media. No thanks.
That’s why scalability and low transaction costs are so important: they enable the true adoption of many new types of applications.
While we are living in a bit quiet period for blockchain demand right now, the demand will most certainly pick up in a year or two.
Fortunately, Zero-Knowledge Proofs will help us with the scalability problem, as we will learn in this blog post.
Let’s get down to the basics.
So, what is Zero-Knowledge Proof exactly?
Enough of pep-talk and background. Let’s face it!
Let’s start with the definition:
In cryptography, Zero-Knowledge Proof is a method by which one party (the prover) can prove to another party (the verifier) that a given statement is true while avoiding disclosure of additional information beyond the fact that the statement is true.
That’s a mouthful. The above is usually related to privacy features.
Imagine this simple example: you want to prove to your friend that you have access to his Twitter account, but you don’t want to reveal the password. How to prove it? You can post a tweet with your friend’s account. Maybe your friend is not convinced yet. To make your point, you post 20 more tweets with his account. Your friend will eventually become convinced that you indeed know the password, even though you haven’t disclosed it.
However, in Ethereum and Layer 2 context, Zero-Knowledge Proofs are currently used only for scaling, not really for privacy-related features.
In the Ethereum L2 context, the more apt definition is:
Zero-Knowledge Proofs enable to prove honest computation without revealing inputs
Yes, “Zero Knowledge” is a misnomer name for Layer 2 roll-ups.
Here’s a tweet from one Haichen Shen, who is the co-founder of Scroll, one of the Ethereum L2 scaling solutions.

Haichen Shen pondered what could be a more accurate name for zk-rollup. (Source: tweet)
Required properties for Zero-Knowledge Proofs:
Zero-Knowledge Proof requires three properties: Completeness, Soundness and Zero-Knowledge.
Completeness
If statement is true, verifier will be convinced by the prover
Soundness
If statement is false, a cheating prover cannot convince verifier it is true (except with some tiny probability)
Zero-Knowledge
Verifier learns nothing beyond the statement’s validity
Btw, who invented these?
Before diving into the tech spec, here’s the human element to provide you a soft landing.
The notion of ‘zero knowledge’ was first proposed in the 1985 by MIT researchers Shafi Goldwasser, Silvio Micali and Charles Rackoff.

Shafi Goldwasser, Silvio Micali and Charles Rackoff
As a peculiar origin story, the original inventors were entertaining an idea of “mental poker”: How to play poker over the phone, so that you could be certain that the other player (which you can’t see) wouldn’t be cheating.
In their paper “The Knowledge Complexity of Interactive Proof Systems”, as the name says, they presented a solution which required repeated interactions between the prover and the verifier. These repeated interactions brought a lot of complexity and a large proof size, which made the solution more of a theoretical than practical success.
Think of the example I presented earlier: proving you know the password of your friend’s Twitter account by posting a tweet under your friend’s name. One tweet might not fully convince your friend, but several tweets most likely will. This is a simplification of what ‘Interactivity’ means.
Much later, in 2012, a non-interactive protocol (zk-SNARK) was invented, which enabled smaller proof sizes and more practical utility.
Looking at the original inventors today, Silvio Micali is the founder of the Algorand L1 blockchain, and thus very much operationally involved in the blockchain space today. Shafi Goldwasser has been lately giving plenty of lectures on the historical origins of Zero-Knowledge. Charles Rackoff continues to be a Professor Emeritus in Computer Science at the University of Toronto.
here are some HYPOTHETICAL examples of ZKP
1. Mortgage Risk Assessment
Typically your bank teller would look at all possible available information about you to assess your creditworthiness for a mortgage. With Zero-Knowledge Proof, it is possible to prove that e.g. the salary and certain other criteria are above thresholds, without actually revealing the numbers, and get the mortgage approved.
2. Proving you are over 18 years old
It feels funny when people keep asking for your ID and you’re already 36 years old (happened to me last week). Usually, they also see all kinds of other data (country, expiry date, etc) from your ID or Passport. It’s not really optimal that one needs to disclose all this irrelevant data at the same go. With Zero-Knowledge Proofs, the verifier can rest assured you are over 18, but without knowing exactly how old, where you are from, or your other personal details.
As you can extrapolate from the example above, you can think of myriad different identity scenarios where ZKPs will be useful.

Zero-Knowledge tech can prove you are over 18 without the need to disclose the number. (Pic from MINA video)
practical BLOCKCHAIN examples already in use
1. PRIVACY COINS
Zcash is a Bitcoin fork that uses Zero-Knowledge tech (zk-SNARK to be specific) to prove that all requirements for a valid transaction are satisfied without revealing additional details, thus enabling private transactions.
2. Mixers
Infamous Tornado Cash protocol (which is controversially banned by the US OFAC) also uses Zero-Knowledge tech to mix incoming coins from different users and thus achieving privacy. Tornado Cash is used by many illegal protocol hackers, but at the same time by people with legitimate needs. (Btw, privacy is a normal thing)
3. Ethereum L2 Zk-Rollups
The most common use case for Zero-Knowledge tech is actually not in privacy but in transaction scalability. The next chapter and major part of this article explore this further.
zk-Rollups for Ethereum L2 scaling solutions
We have finally arrived at the actual topic we want to deep-dive into today.
How Zero-Knowledge Proofs support scaling in certain Ethereum L2 solutions. These L2 solutions are referred to as zk-Rollups and the leading ones are developed by teams at Matter Labs (zkSync), Scroll, and Polygon.
Ironically, the majority of these zk-Rollups solutions do not have transaction-shielding privacy features.
We earlier mentioned three requirements for zk-Rollup: Completeness, Soundness and Zero-Knowledge.
The majority of zk-Rollups don’t have the 3rd property of Zero-Knowledge. Transactions on these L2 chains are not really private by nature. (An exception to the rule is Aztec Network, which has privacy-preserving features)
As we learned earlier, the ‘Zero-Knowledge’ is a bit misleading in the context of zk-Rollups.
The Zero-Knowledge tech is used to reduce the size of the transaction CALLDATA that is published to the blockchain. Operating data is a heavy burden on blockchains, and reducing CALLDATA size decreases transaction costs and increases speed. Blockchain data can be compressed to generate proof to perform a state change.
In other words, Zero-Knowledge tech is used to calculate validity proofs of transactions that are posted to L1, which then can be independently verified. This is faster than doing certain computations again, which brings the scalability benefit (e.g. compared to Optimistic Rollups)
We’ll get down to this in much more detail in a sec.
Let’s first explore two major implementations of Zero-Knowledge Proofs: ZK-SNARK and ZK-STARK.
Different ZKP versions: ZK-SNARK and ZK-sTARK
There are two major implementations of Zero-Knowledge tech: ZK-SNARKs and ZK-STARK.
ZK-SNARKS
Like we learned earlier, Zero Knowledge tech was more an academic than practical success for decades. Lot of research was done by many scientists to change the ‘interactive’ feature to ‘non-interactive’. This was a major improvement and got introduced under the name ZK-SNARK.
ZK-SNARK term was first introduced in 2012 in a paper co-authored by Alessandro Chiesa, a professor at UC Berkley.
Interestingly, Mr Chiesa is also a co-founder at Zcash and StarkWare. And author of libsnark, C++ library for ZK-SNARKs. Impressive bio indeed — he had all cryptography pioneers surrounding him throughout his studies. His M.Sc. thesis was supervised by Ron Rivest (co-inventor of RSA) and his PhD by Silvio Micali (co-inventor of ZKP and co-founder at Algorand) at MIT.

Alessandro Chiesa, co-author of a paper in 2012 in which he coined the term zk-SNARK. See his website here.
So what do these 5 letter acronyms stand for?
zk-SNARK = Zero-Knowledge Succinct Non-interactive ARgument of Knowledge
zk-STARK = Zero-Knowledge Scalable Transparent ARgument of Knowledge
Fortunately, these are pretty descriptive. Let’s have a look at each word separately in SNARKs:
"Zero-knowledge": We already know this part. The proof itself reveals no information about the underlying information.
"Succinct": This means that the proof is short and can be verified quickly, making it more efficient than other types of proofs.
"Non-interactive": This refers to the fact that the proof does not require any interaction between the prover and verifier. In other words, the proof can be verified without any communication between the parties. This was the major technical breakthrough.
"Argument of Knowledge": This means that the proof provides a convincing argument for the statement/knowledge being made, but it doesn't necessarily provide any additional information.
So all in all, ZK-SNARK is a tool that allows one party to prove to another party that they know a certain value, without revealing the value itself, and that this proof can be done quickly, without any interaction and only the knowledge aspect is proved, not the information itself.
ZK-SNARKs has been around for 10+ years and compared to ZK-STARKs, has naturally built larger community and developer tools over time. Both have their distinctive features and suitable use cases, though. Let’s continue and learn about ZK-STARKs.
ZK-STARKs
ZK-STARK was introduced much later in 2018 by Eli Ben-Sasson, Iddo Bentov, Yinon Horeshy and Michael Riabzev.

Co-authors of ZK-STARK: Eli Ben-Sasson, Michael Riabzev and Iddo Bentov. Yinon Horeshy is also a co-author, and apparently follows the zero-knowledge principle the most: I couldn’t find any photo of him online.
The first few pages of the original research paper of ZK-STARKs is a fascinating read. I’ll just copy+paste few snippets directly, and you get the hang of it:
“Zero-knowledge (ZK) proof systems are an ingenious cryptographic solution to this tension between the ideals of personal privacy and institutional integrity, enforcing the latter in a way that does not compromise the former. Public trust demands transparency from ZK systems, meaning they be set up with no reliance on any trusted party, and have no trapdoors that could be exploited by powerful parties to bear false witness.”
“For ZK systems to be used with Big Data, it is imperative that the public verification process scale sublinearly in data size. Transparent ZK proofs that can be verified exponentially faster than data size were first described in the 1990s but early constructions were impractical, and no ZK system realized thus far in code (including that used by crypto-currencies like Zcash™) has achieved both transparency and exponential verification speedup, simultaneously, for general computations”
“Here we report the first realization of a transparent ZK system (ZK-STARK) in which verification scales exponentially faster than database size, and moreover, this exponential speedup in verification is observed concretely for meaningful and sequential computations, described next”
Let’s revisit the acronyms:
zk-SNARK = Zero-Knowledge Succinct Non-interactive ARgument of Knowledge
zk-STARK = Zero-Knowledge Scalable Transparent ARgument of Knowledge
Next, let’s break down each word separately in zk-STARK:
"Zero-knowledge": (the same as in SNARKs.)
"Scalable": This means that the proof can be used to prove statements about a large amount of data, without needing to include all of the data in the proof. This allows zk-STARKs to be more efficient than other types of zero-knowledge proofs, particularly when the amount of data is large. zk-STARKs' proof sizes do not depend on the amount of data.
"Transparent": zk-SNARKs use non-public randomness to generate a key and rely on a trusted setup (which can be an attack surface). zk-STARKs do not require any such setup and can be computed without any trusted third party, hence they are transparent.
"Argument of Knowledge": (the same as in SNARKs.)
Okay, let’s do some comparisons between SNARK and STARK:

Image source: Elena Nadilinski's slides from Devcon4
As we can see, the proof size of SNARKs is over 100x smaller than STARKs. The proof is short and can be verified quickly.
However, if you are operating on a large amount of data, ZK-STARK might be a better choice. ZK-STARKs proof size does not depend on the amount of data, and thus it can prove statements about much larger amounts of data than ZK-SNARKs.
Then there are some other (theoretical/long-term) considerations. One is Post-Quantum Security. Zk-STARKs use hash functions that are thought to be resistant to quantum computer attacks. Zk-SNARKs are considered not to be quantum secure because they use Elliptic Curve Discrete Logarithm Problem (ECDLP). A sufficiently powerful quantum computer would be able to crack the ECDLP in polynomial time. The line is getting a bit blurred lately, and there is ongoing research making SNARKs quantum secure as well.
Next, let’s pick ZK-SNARK and explore it a bit deeper under the hood — how the tech actually works. If you’re reading about Zero Knowledge for the first time, you are probably already overwhelmed by the new terms and concepts. Congratulations on making it this far.
And apologies in advance — there will be much more new jargon in the next chapter. Feel free to skip the next chapter if you’d rather get a high-level understanding first and prefer to learn the tech part later.
ZK-SNARKS PROOF GENERATION UNDER THE HOOD
An article about Zero-Knowledge Proofs wouldn’t be complete without a small section on how things work under the hood.
I originally planned to write a comprehensive step-by-step explanation of how the moon math works. I quickly realized, though, that this would 10-20x the length of the article, and take ages to write — which would not make sense. There are incredibly many math/cryptography concepts involved. All in all, it is a nontrivial process. There are some extremely complex bits (polynomial commitments — phew). That said, most of the concepts are not that hard at all. They simply take a lot of space to explain.
So, in this blog post, I’ll give a rough explanation of each step and give pointers to learn more about math should you be interested.
ZK-SNARK proof generation step-by-step:

Image source: Isram Bashir, Mastering Blockchain (book)
Let’s explore each step separately.
Computation:
To be able to utilize zk-SNARKs, you first need to convert the problem into the right form. This form is called QAP (Quadratic Arithmetic Program).
QAP is an equation composed of a vector of values and three vectors of polynomials. Transforming the code of a function into one of these is complicated, and we need to take a series of steps to get there.

Image source: Zcash “What Are zk-SNARKs”
Arithmetic Circuit:
The first step is to convert the computation into an arithmetic circuit, which is a collection of logic gates (such as addition, subtraction, multiplication, division) and wires that perform specific operations on input variables.
See an example on the left: (a+b) * b * c is converted into an arithmetic circuit.
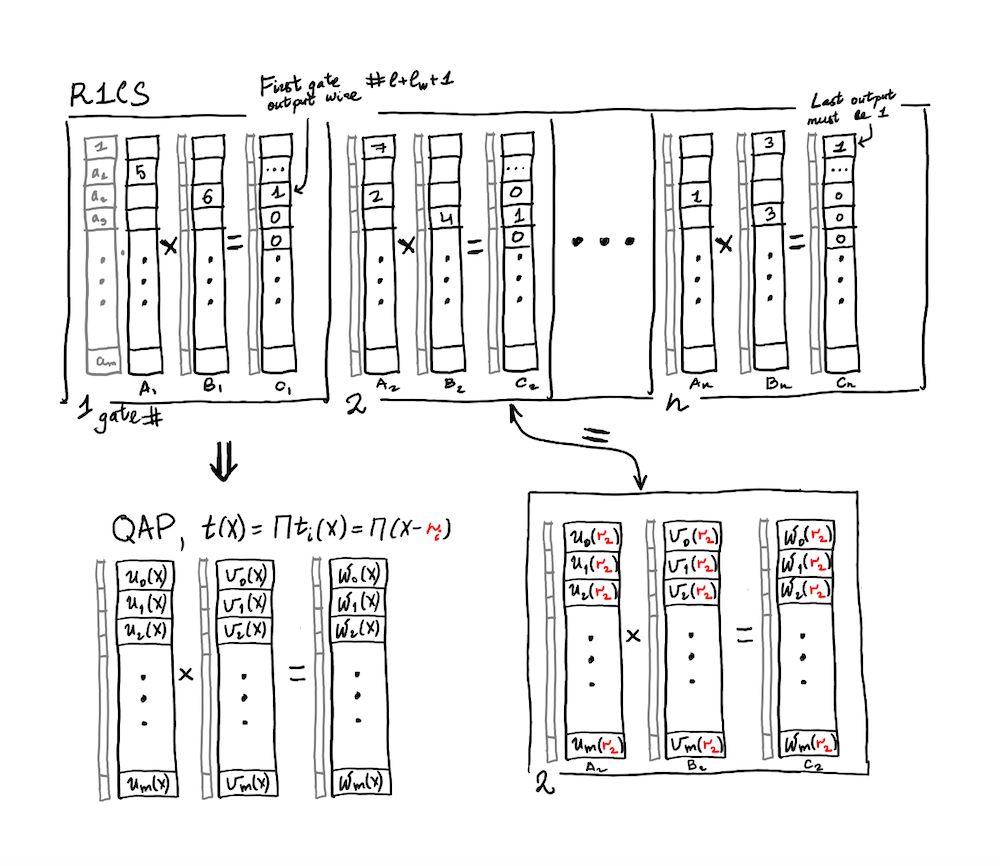
R1CS (Rank-1 Constraint System)
R1CS format is useful because it provides a way to translate complex arithmetic circuits (from the previous step) into a simple mathematical structure that can be analyzed and verified efficiently.
The important thing to understand is that R1CS is not a program that produces a value from certain inputs. Instead, A R1CS is a verifier, it demonstrates that an already complete computation is correct.
R1CS involves three vectors a, b, and c. The prover also provides vector s (“witness”). These vectors provided, the following equation needs to be satisfied:
a⋅s + b⋅s - c⋅s = 0
The dot (.) inside the equation refers to the dot product of vectors.
This transformation into R1CS is done for each of the logic gates from the previous step. For example, if we would have 5 logic gates in the first step, at the end of the second step, we would have a series of 5 vectors for each a, b, c.
To fully understand how R1CS works, we would need to go through vector and dot product math. In case you’re interested this and this are two good primers. This part is not that difficult, it just takes a lot of space to explain fully.
Alright, so we have our R1CS ready now. This is only an intermediate representation of getting to QAP (to enable verification without revealing the secret variables).
You need to learn to love these types of illustrations if you’d like to learn R1CS and QAP. For now, forget trying to figure this graph out, it’s just for illustration… (Source / Author: Misha Volkhov)
QAP (Quadratic Arithmetic Program)
QAP is a method for representing the vectors (from R1CS) as a system of polynomials.
Why do we want to do this? It makes the prover's task simpler and more efficient. With QAP we can check all of the constraints at the same time on the polynomials (instead of checking the constraints individually like in the R1CS stage).
So, how can we create the QAP polynomials from the R1CS vectors?
This gets tricky to summarize in short. Basically, we want the polynomials to implement the exact same logic (but in polynomial format instead of vectors). When we evaluate the polynomial at each coordinate x, it should represent one of the constraints. E.g. x=1 would give us the first set of vectors (that we got in the R1CS stage), x=2 would give the second set of vectors, x=3 third set etc.
This transformation can be completed with Lagrange interpolation. If you have a set of (x, y) coordinates (points), with this method you can create a polynomial (graph) that passes through all of these (x,y) coordinates.
Ok. So you have a bunch of polynomials now. What’s the point? Now, you can check all of the constraints with a single check on the polynomials utilizing the dot product check. (instead of checking them individually like in the R1CS stage).
Certain math tricks make operating polynomials really efficient.
Vitalik has written a good explainer article on QAP which I used for my summary above. Here’s another clear explainer.
ZK-SNARK:
Done. We did skip some steps and concepts, but now we can use the QAP in the ZK-SNARK protocol to prove the assertation between the prover and the verifier.
So, what parts did we actually omit describing ZK-SNARK generation?
Quite many parts, here’s a non-exhaustive list:
Polynomial commitments, a kind of polynomial "hash" that allows to verify the equation between polynomials in a very short amount of time. Major schemes are called: bulletproofs, Kate and FRI. These are really complex concepts, and you need to understand everything else before it makes sense to try to understand these. I haven’t personally tried to wrap my head around these yet.
Fast Fourier Transform (FFT). The FFT algorithm allows for the efficient computation of the coefficients of polynomials, essentially making ZK-SNARK generation and verification fast enough to be practical. Also, probably not worth figuring these out unless you plan to become ZK-engineer.
PLONK. PLONK is the most modern zk-SNARK proof system. Previous zk-SNARK versions required a new trusted setup for any new circuits. PLONK has a universal trusted setup. It can be initiated once and used by all circuits. It’s also updatable (new randomness can be added). More PLONK reading resources here.
Homophormic encryption and Homophormic hiding. This is actually quite an interesting and easy-to-understand concept. You can find an explanation in this article.
Elliptic Curve Pairing (and Elliptic Curve Cryptography).
All of the above also requires an understanding of basic cryptography such as public key encryption, digital signatures etc. This is a great book refreshing memory on these basic concepts. It’s beginner-friendly but goes deep enough. I really enjoyed reading it.
It is really hard and complex
Do I understand the inner mechanics of every step? Far from it. One basically needs years of math, computer science and cryptography experience to fully understand the stack. Perhaps you can even spot some inaccuracies in the explanation above. In case, please let me know.
That said, if you’re an engineer and would like to enter the rabbit hole, there’s plenty of material, courses & even boot camps, compared to just a few years ago. For e.g. 0xParc has a lot of resources, and they even host this cool ZK Spring Residency in Vietnam later this year.
“Ok tnx - I didn’t understand much from the previous chapter. What should I remember?”
ZK-SNARKs is all about verifying the computation, in the context of Ethereum L2 scaling.
The main idea you need to remember is that ZKPs allow you to verify millions of steps of calculation in a very fast way. There is no need to redo the computation (that would take a long time) to verify its honesty.
Ok. Enough math and acronyms for this blog post.
Let’s proceed to a higher level and see how ZKPs are utilized in Ethereum scaling.
Ethereum scaling: zero-knowledge rollups
As we covered earlier, Zero-Knowledge tech in Ethereum is mostly used for scaling, in the form of L2 ZK-Rollups.
You’ve probably heard of Optimism and Arbitrum. They were the first Ethereum L2 scaling solution using ‘Optimistic Rollups’ technology. Optimistic rollups are considered “optimistic” because they assume off-chain transactions (L2 transactions) are valid and don't publish proofs of validity for transaction batches posted on-chain in L1.
Optimistic rollups rely on the fraud-proving scheme and “a challenge period” when anyone can challenge the results of rollup transaction. This separates optimistic rollups from zero-knowledge rollups that publish cryptographic proofs of validity for L2 off-chain transactions.
The mainnet of both Optimism and Arbitrum went live in 2021. They helped to scale Ethereum and decrease transaction costs. However, there is still a lot of room for improvement in scaling.
Optimistic Rollups have always been a bit of a temporary solution to scaling. Zk-Rollups are more complicated but will enable even more scaling when the tech improves. Let’s dig into the specific comparison.
Optimistic rollup vs. zk-Rollups
You could almost write a book about the differences between Optimistic Rollups and Zk-Rollups. We’ll keep it short in this blog post.
So, what are the advantages of Zk-Rollups? Scalability, fast withdrawal, and privacy features
The main advantage of Zk-Rollups is scalability — they can process more transactions, and scale even further in the future when the tech improves (over 2000 TPS compared to 500 TPS with Optimistic Rollups).
Zk-Rollups also have a fast withdrawal period between L1 <-> L2 (next block, compared to one week with Optimistic Rollups).
Most Zk-Rollups currently use Zero-Knowledge tech only for the calculation of validity proofs = scaling the throughput. In the future, privacy-related features are more easier and natural to implement. One more plus point for Zk-Rollups.
Disadvantages of zk-Rollups? Complexity, EVM (in)compatibility and computation costs
However, the scalability comes with a considerable ‘cost’ in other areas. Zk-Rollups are extremely complex. There are not too many computer scientists on the planet who truly understands the entire stack. This also makes auditing the code more challenging. There’s a lot of effort and resources poured into the ZK space though, and many have been surprised about the speed of development during the last couple of years.
Implementing EVM (Ethereum Virtual Machine) is also much harder for ZK-Rollups. Different ZK-Rollups have done certain compromises and only support the majority of the OP codes. Thus, the Solidity code might require some slight changes to work on ZK-Rollup. Vitalik also wrote an article about EVM compatibility and created different categories. We’ll explore EVM compatibility in more detail later in this article.
Finally, the off-chain computation costs can be high on ZK-Rollup. Generating the proofs require specialized hardware. Some ZK-rollup projects (Scroll) are even exploring utilizing ASICs to generate these proofs and thus create a new decentralized proof market (a bit like Bitcoin mining, but not quite the same).
To put all the above arguments above in a table for easier comparison we get this:
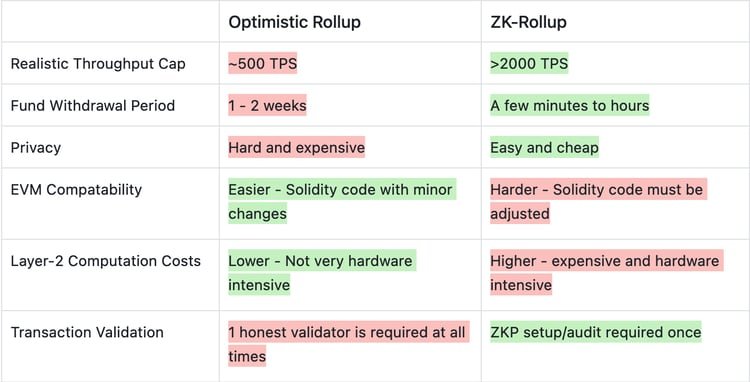
Source: TokenInsight
Now that you understand the main differences, Vitalik’s prediction in 2021 on Optimistic Rollups and ZK-Rollups is fairly logical:
“In general, my own view is that in the short term, optimistic rollups are likely to win out for general-purpose EVM computation and ZK rollups are likely to win out for simple payments, exchange and other application-specific use cases, but in the medium to long term ZK rollups will win out in all use cases as ZK-SNARK technology improves.”
The “medium to long term” time frame up there, however, has moved up significantly with the recent zk-EVM compatibility that was thought to be years ahead.
If you’d like to read a more detailed comparison between zk-Rollups and Optimistic Rollups, here’s a deep dive by Suning Yao. Vitalik has also written a good article on Rollups: An Incomplete Guide to Rollups, which I’ve used as the basis for my summary above.
And oh btw, the Optimistic Rollup vs. ZK-Rollup is a heated debate. Optimistic Rollup people don’t seem to be happy about the hype around ZK-Rollups… pick up your popcorns and enjoy this tweet thread, and the response thread.
From A SIMPLE ZK-Rollup to ZK-EVM
To be precise, ZK-Rollup and ZK-EVM are two different things. Or rather, ZK-EVM is the advanced version of ZK-Rollup, with EVM compatibility.
ZK-Rollups were developed already a couple of years ago as L2s for Ethereum (think of Loopring or the early versions of zkSync). They execute transactions faster than optimistic rollups, thanks to cryptographic proofs that verify their transactions in a batch. However, the earliest ZK-rollups could only perform simple transactions (think of transfers, atomic swaps), and not full-scale smart contracts. They were not EVM (Ethereum Virtual Machine) compatible.
ZK-EVMs are advanced Zk-Rollups and support the EVM. This enables (near) direct portability of Solidity code, allowing developers to build just like they would be building on the Ethereum L1 mainnet. ZK-EVMs’ speed of development has indeed been fast, surprising Vitalik himself as we saw above. Three ZK-EVM projects are heading towards mainnet launch this year in 2023 (zkSync, Scroll and Polygon zk-EVM).
Different zk-EVMs — compatibility DIFFERENCES
Have a quick look at the previous graph in this article — row 4. We saw that “EVM Compatibility” with zk-Rollups says “Harder compatibility - Solidity code must be adjusted”.
This particular aspect is what separates the different zk-EVM projects from each other.
Generally, different zk-EVMs make different compromises with performance and EVM compatibility. Or in other words, between speed and practicality.
Vitalik has written an entire blog post about the categorization. He defined four categories: Type 1, Type 2, Type 3 and Type 4. Type 1 is the most compatible, but has the slowest prover times. Type 4 is the least compatible, but has the quickest prover times.
In the current stage of development, achieving perfect compatibility has a diminishing return.
Thus, none of the four different types is necessarily better than the other. It’s a good thing that different projects explore different tradeoffs.
The differences get technical and nuanced, and I’ve summarized Vitalik’s categorization here for the big picture.
Vitalik’s zk-EVM categorization:
Type 1 zkEVMs: Fully Ethereum-equivalent
Advantage: perfect compatibility
Disadvantage: prover time
Who’s building it? Taiko and the ZK-EVM Community Edition (developed by Ethereum’s Privacy and Scaling Explorations, the Scroll team, Taiko and others) is aiming to be Type-1 ZK-EVM.
Type 2 zkEVMs: Fully EVM-equivalent (not Ethereum-equivalent)
Advantage: perfect equivalence at the VM level
Disadvantage: improved but still slow prover time
Who's building it? Scroll, Polygon zkEVM and Consensys zkEVM are aiming to be Type-2, though are currently in Type 3.
Type 3 zkEVMs: Almost EVM-equivalent
Advantage: easier to build, and faster prover times
Disadvantage: more incompatibility
Who's building it? Scroll, Polygon zkEVM and Consensys zkEVM are aiming to be Type-2, though are currently in Type 3.
Type 4 zkEVMs: High-level-language equivalent
Advantage: very fast prover times
Disadvantage: more incompatibility
Who's building it? ZKSync is a Type 4 system, though it may add compatibility for EVM bytecode over time.
Finally, it’s also good to note that zk-EVM projects can over time develop and shift to lower-numbered types or higher-numbered types.

Vitalik’s categorization of zkEVM differences: the tradeoff between Compatibility and Performance (source)
COMPARING ZK-eVM projects
Type-4 zkEVM compatibility (EVM is Language-level compliant).
Utilizing SNARKs.
ZkSync supports Solidity (translated in Yul language), Vyper and LLVM.
Currently in ‘baby mainnet’ (= limited access). The actual mainnet is to be launched in 2023. ZkSync has promised to go open source by their next release (Fair Onboarding Alpha onwards).
What can I do now? (Feb/2023) Use zkSync in the testnet! And if you’ve been invited, also in their ‘baby mainnet’. zkSync has been the first to market and has already a fairly wide variety of dapps.
Aims to be Type-2 zkEVM compatible (with Bytecode-level compatibility).
Utilizing SNARKs.
Aims to be ‘faithful’ to EVM compatibility — Solidity is directly compiled without any other language in between.
Scroll collaborates with Ethereum Foundation’s Privacy and Scaling Explorations team to eventually get as close to Type-1 compatibility as possible.
Currently in Private pre-alpha testnet, planning to launch mainnet in 2023. Open-source.
What can I do now? (Feb/2023) Register in the pre-alpha testnet!
Polygon zkEVM (ex Hermez):
Aims to be Type-2 zkEVM compatible (with Bytecode-level compatibility via interpreter).
Utilizing both SNARKs and STARKs.
Currently in public testnet, mainnet planned for early 2023. Open-source.
Polygon has five different teams building different Ethereum scaling solutions (Polygon zkEVM, Polygon Miden, Polygon Edge, Polygon Zero, Polygon PoS). Yeah, it’s confusing. I’ve understood that they have a lot of expertise under the same roof, which has enabled them to learn a lot from each other.
What can I do now? (Feb/2023) Explore their public testnet!
Aims to be Type-1 zkEVM compatible (with Bytecode-level compatibility)
Thus, Taiko plans to prioritize compatibility over proof generation cost.
Taiko plans to support the same hash functions, state trees, transaction trees, precompiled contracts, and other in-consensus logic, which make Taiko’s developer experience as smooth as it can get (no cognitive load — everything works the same way as in Ethereum L1)
Taiko collaborates with Ethereum Foundation’s PSE team
“Taiko A1” Alpha-1 testnet is phasing out on 15th Feb 2023, and new Alpha-2 testnet launching around a month after
What can I do now? (Feb/2023) Try Taiko’s Alpha-2 testnet in March 2023 when it will launch
Type-4 zkEVM compatible (with language-level EVM compatibility).
Utilizes STARKs. It’s technically more secure than ZK-SNARKs but takes longer to verify and requires more gas.
Supports Cairo language and Solidity (via transpiler).
Alpha mainnet launched in Q4 2021 but remains limited. Closed source.
What can I do now? (Feb/2023) Explore Starknet’s mainnet!
Privacy & Scaling Explorations team at Ethereum Foundation (ex. AppliedZKP):
The PSE team is not really an L2, but worth mentioning here, because they have close collaboration with the Scroll team to develop Type-1 EVM
PSE explores new use cases for zero-knowledge proofs and other cryptographic primitives through research and proof-of-concepts.

Comparison of zk-Rollup projects, and their level of EVM compatibility. (Source)
OTHER
Aztec Network: Aztec Network is also L2 in Ethereum, with the speciality of being entirely private (shielded transaction). But Aztec is really different to the other rollups. It’s not a traditional roll-up with its own liquidity. Protocols don’t deploy their whole protocol on Aztec, instead, they add a set of smart contracts using Actec Connect, which enables them to use protocol through it. Major DeFi protocols have their integrations in place with Aztec. This method preserves liquidity and composability on L1. Aztec is not EVM compatible.
Latest news
While I was writing this article, there was interesting news coming up. Here’s just a few of the many.
Consensys zkEVM: On December 13th 2022, Consensys Launched a private beta zkEVM Testnet to scale Ethereum. Consensys’s zkEVM handles native EVM bytecode, thus enabling support for existing developer tools and infrastructure. On Vitalik’s categorization, Consensys zkEVM is considered to be Type-2, just like Scroll and Polygon zkEVM.
HyperOracle: HyperOracle is also a really early team, having just raised 3 MUSD. Hyper Oracle is Web3 zkMiddleware and aims to utilize Hyper Oracle Node to take and cache the states of smart contract, and generate proof of them so that any data can be transferred across different blockchains, blocks, and time.
Sovereign: Sovereign came to the public on Jan 30th, 2023 with 7.4 MUSD fundraising. They aim to be an open, interconnected rollup ecosystem. Their goal is to enable all developers to deploy seamlessly interoperable and scalable rollups that can run on any blockchain. Sovereign SDK is the framework they develop to aim for creating secure and interoperable sovereign zk-rollups.
Latest news: The latest news on Zero Knowledge you can find on Coindesk’s tag search here.
ZK-EVM RACE TO MAINNET
There’s been massive funding to different ZKP teams to build L2 scaling solutions on Ethereum. In the previous chapter, you learned about all the players in the field: zkSync, Scroll, Polygon zkEVM, StarkNet, Taiko, Consensys, etc.
There’s been a race to be the first one to release general-purpose zkEVM on mainnet, which would support smart contracts and porting dapps.
Three different teams have already announced they will bring their zk-EVM solutions to the mainnet stage during this year 2023.
As of writing this article in Feb 2023, that hasn’t happened yet. zkSync is closest to the goal, having launched ‘baby mainnet’, which means it is still in internal testing without public access.
If you are reading this article just a few months after being published, things most likely have already changed.
Final thoughts
Ethereum is the most popular smart contract blockchain and it has by far the largest amount of developers of any public blockchain. However, the Ethereum mainnet has become expensive and slow. Thus, there’s a need for scaling. Ethereum is following the ‘roll-up centric roadmap’.
Optimistic Rollups (Optimism and Arbitrum) command the largest Total Value Locked right now. Both of them have mainnet live and most important dapps ported. Optimism has also its OP token launched. Arbitrum is expected to launch its token soon.
The scalability which Optimistic Rollups provide won’t be enough for the future block space demand.
Thus, Zero-Knowledge rollups (ZK-Rollups) have been developed, and they promise much more scalability and privacy-related functionality. ZK-Rollups are technically much more complex to build, but a lot of money has been poured into several teams, even to the extent that the development has become a bit too fragmented.
The recent game changer with zk-Rollups has been the EVM support (= zk-EVMs). If you are a Solidity developer, this is like grace from heaven: you can pretty much deploy your code on zk-EVM like you have on Ethereum L1 mainnet. You need to know absolutely nothing about Zero-Knowledge Proofs.
However, zk-EVMs are different under the hood, and they make a different set of compromises between Performance and Compatibility (From Type 1 to Type 4).
Vitalik personally hopes that all zk-EVM projects would eventually become “Type 1”. That is, fully Ethereum-equivalent, which would not only enable using the same Solidity code, but all the developer tools, same OP codes, etc. Vitalik also hopes that Ethereum itself would improve to become more ZK-SNARK friendly.
However, it is still a faraway vision.
All zkEVMs support Solidity code. True Ethereum-equivalence is still a much larger challenge and has unsolved technical aspects. Most ZK-EVM projects are ‘selling’ their 3+ year future vision of their capabilities. Only time will tell how these promises are delivered.
Nevertheless, there is a lot of innovation and engineering happening as we speak, both in ZK-EVMs and in Ethereum itself. It’s a good thing that different teams have different emphases on the Performance vs Compatibility spectrum.
Thank you
I’ve done a lot of research and reading while writing this article.
Credits to Vitalik Buterin, Massimo Bertaccini, Imran Bashir, Alex Gluchowski, Haichen Shen, David Schwartz, Eshita Nandini, Jerry Sun, Panther protocol team, Eli Ben-Sasson, Iddo Bentov, Yinon Horesh, Michael Riabzev, Shafi Goldwasser, Alessandro Chiesa, Madars Virza, Eran Tromer, Suning Yao, Maksym Petkus, Alex Connolly, Elena Nadolinski, Misha Volkhov, L2 Beat.
My article rests on the shoulders of your writings and research for the most part. I’ve provided the full reference list below.
Email newsletter
If you’d like to stay updated on my future crypto articles, you can subscribe to my newsletter here.
References
Ethereum’s documentation - ZK-rollups: Great overview of the tech and terminology without geeking out the underlying math
Cryptography algorithms - A guide to algorithms in blockchain, quantum cryptography, zero-knowledge protocols, and homomorphic encryption, March 3rd, 2022 (Massimo Bertaccini) — Personal note: Great book if you’d like to learn modern cryptography from scratch. Fascinating and easy-to-understand read, yet it explains through all the nitty-gritty math
Mastering Blockchain, Imran Bashir - Amazing handbook on nearly all tech concepts in blockchain (The ZKP part is limited in length, though. Bertaccini’s book above is better to understand ZKPs deeply)
The ZK Everything Report, by Eshita Nandini & Jerry Sun (Messari). A great summary.
A16Z Zero Knowledge Canon Great compilation of ZK-related research if you want to go as deep as possible in the research. Not for beginners necessarily.
zkEVMs – Everything you need to know, by Patherprotocol
A Brief Dive Into zk-SNARKs and the ZoKrates Toolbox on the Ethereum Blockchain, Cornell Blockchain
zk, zkVM, zkEVM and their Future, by Suning Yao
Why and How zk-SNARK Works: Definitive Explanation, Maksym Petkus
Scalable, transparent, and post-quantum secure computational integrity (original paper on ZK-STARK), Eli Ben-Sasson, Iddo Bentov, Yinon Horesh, Michael Riabzev 2018.
What are zk-SNARKs? (in Zcash)
Succinct Non-Interactive Zero Knowledge for a von Neumann Architecture, Eli Ben-Sasson, Alessandro Chiesa, Eran Tromer, Madars Virza (One of the most prominent ZK-SNARK paper - proposed the first universal design).
The Zero Knowledge Frontier: On SNARKs, STARKs, and Future Applications, May 6th, 2022 https://thetie.io/
Polygon Miden Deep Dive: A STARK Based zk-Rollup, Pedro. Feb 26th, 2022.
Ground Up Guide: zkEVM, EVM Compatibility & Rollups, Alex Connolly. Aug 9th, 2022
(Almost) Everything about Rollup, Suning Yao June 14th, 2022
What is a zkEVM? Alchemy blog. June 21st, 2022
Constraint Systems for ZK SNARKs, Alex Pinto. March 6th, 2019. Good explainer on R1CS and constraint systems
Article’s banner image at top of this page, by Midjourney. Prompt: “ethereum, zero knowledge, in space, artistic, optimistic, positive, happy, dark background”. Simply amazing.
Vitalik Buterin’s writings about Zero-Knowledge over the years in chronological order:
Vitalik has written a lot of great articles on Zero-Knowledge Proofs. Most of them are not beginner-friendly and go deep into math. For a high-level understanding, I would recommend reading article number 9 and 14 below.
I would not try to understand ZK-stuff only through Vitalik’s articles (many have tried…). There’s better beginner-friendly material, e.g. I really enjoyed this book to refresh my mind on basic cryptography.
Quadratic Arithmetic Programs: from Zero to Hero - 10th Dec, 2016 (this additional article and visualizations help you to understand the math in Vitalik’s article)
Zk-SNARKs: Under the Hood - 1st Feb, 2017
STARKs, Part I: Proofs with Polynomials - 9th Nov 2017
STARKs, Part II: Thank Goodness It's FRI-day - 22nd Nov 2017
STARKs, Part 3: Into the Weeds - 21st Jul, 2018
The Dawn of Hybrid Layer 2 Protocols - 28th Aug, 2019
Fast Fourier Transforms - 12th May, 2019
Understanding PLONK - 22nd Sep, 2019
An Incomplete Guide to Rollups - 5th Jan, 2021
An approximate introduction to how zk-SNARKs are possible - 26th Jan, 2021
The Limits to Blockchain Scalability - 23rd May, 2021
How do trusted setups work? - 14th Mar, 2022
Some ways to use ZK-SNARKs for privacy - 15th Jun, 2022
The different types of ZK-EVMs - 4th Aug, 2022